
[Team_ForV] AI Models
카테고리: Team_ForV
태그: AI
음성 합성은 어떻게 이루어질까?
대부분의 음성 합성 네트워크는 두 단계로 이루어진다!
1) Mel-spectrogram 생성
2) waveform 생성
이 프로젝트에서는 Glow-TTS와 HiFi-GAN을 사용하여 위의 두 가지 단계를 수행하고, 그 결과물을 이용하여 음성 합성 과정을 수행한다.
각각에 대해서 차근차근 알아보자!
Mel-spectrogram의 생성
학습에 필요한 음성 녹음을 마쳤다면, 녹음한 음성 데이터들로 목소리 학습을 진행해야 한다.
음성 데이터를 raw data를 그대로 사용하면 파라미터가 너무 많아지기도 하고 데이터 용량이 너무 커지므로
보통 Mel-spectrogram을 많이 사용한다고 한다.
음성파일에서 의미있는 정보를 얻기 위해선 음성 데이터를 컴퓨터가 다루기 쉽도록 가공해주어야 하는데, 여기서부터 ‘신호처리’의 영역으로 들어간다.
- 신호(Signals)란?
Signal은 시간에 따른 특정 양의 변화이다.
Audio같은 경우 공기의 압력이 이에 해당하는데,
이 정보를 디지털 방식으로 얻는 방법은 시간에 변화에 따른 기압 sample을 채취하는 것으로, 데이터를 샘플링하는 속도를 조절하여 얻을 수 있다.
이렇게 얻어낸 파형 신호에 대해 컴퓨터로 해석하고, 분석 및 수정을 하는 것이다.
아래 예시는 librosa 라이브러리를 이용하여 wav파일로부터 파형 신호를 얻어내는 예제이다.
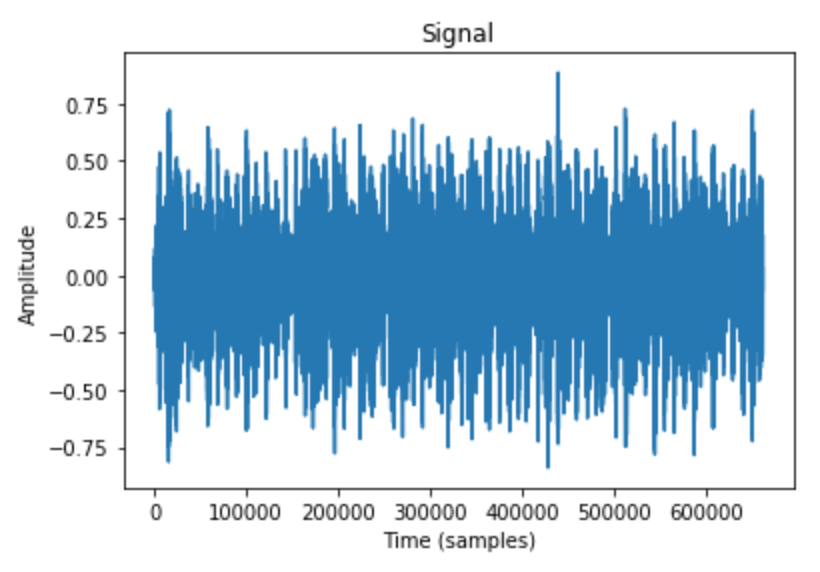
import librosa
import librosa.display
import matplotlib.pyplot as plt
y, sr = librosa.load('./example_data/blues.00000.wav')
plt.plot(y)
plt.title('Signal')
plt.xlabel('Time (samples)')
plt.ylabel('Amplitude')
이렇게 얻어낸 signal 자체만으로는 의미가 없고, 이로부터 유용한 정보를 뽑아내기 위해 ‘푸리에 변환’이라는 개념이 등장한다.
- 푸리에 변환(Fourier Transform)이란?
푸리에 변환을 간단히 말하자면 ‘입력 신호를 다양한 주파수를 가지는 주기함수들로 분해하는 것’이다.
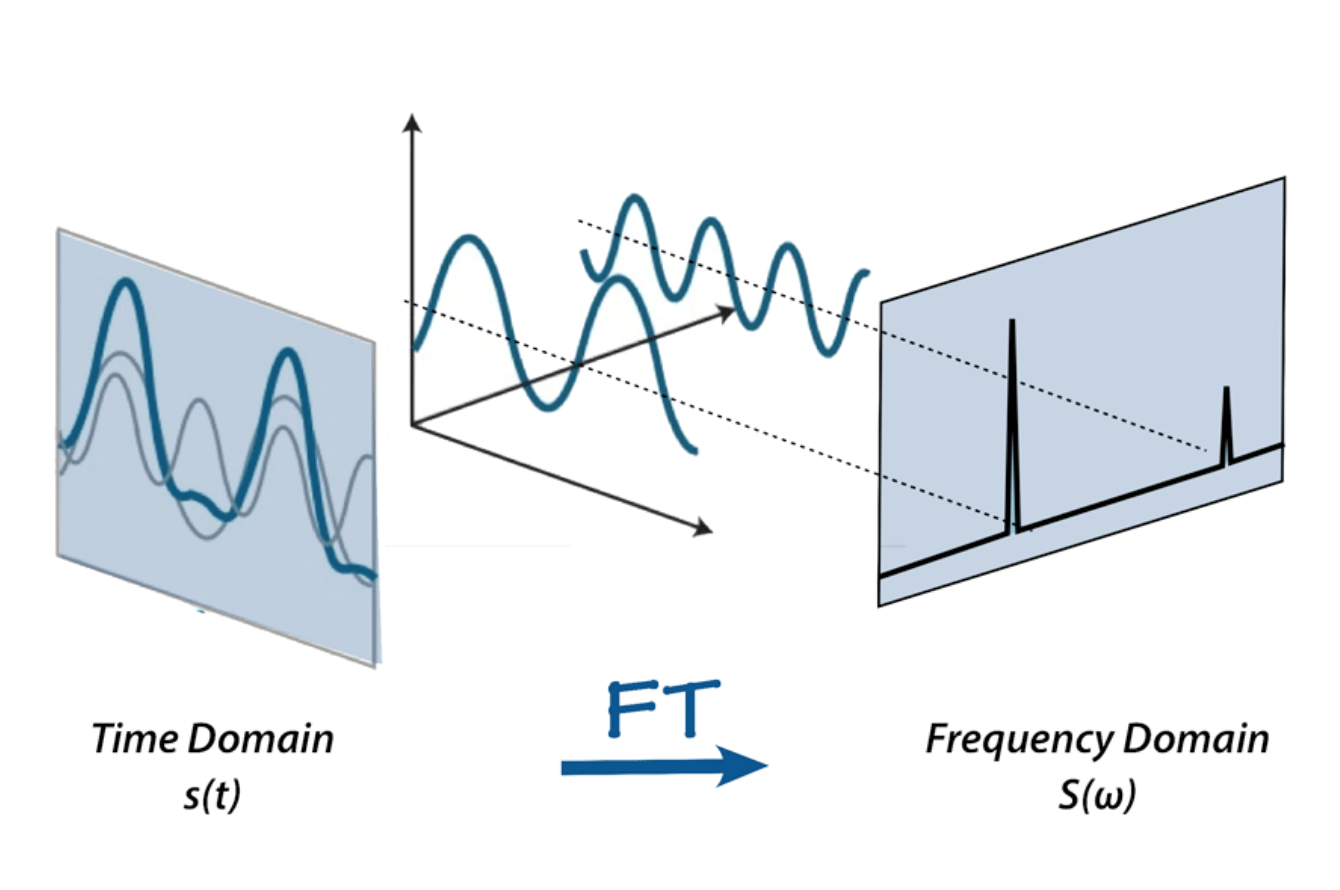
오디오 신호는 여러 개의 단일 주파수 음파들로 구성되는데,
time domain에서는 진폭(amplitude)만 얻어낼 것을 ‘푸리에 변환’을 통해
frequency domain에서 주파수(frequency)와 진폭(amplitude)를 가지는 주기함수를 얻어내는 것이다.
이렇게 나온 결과를 spectrum이라고 한다.
- Fast Fourier Transform(FFT)
푸리에 변환의 한 예로 fast Fourier transform (FFT)는 신호처리에서 널리 쓰이는 알고리즘인데,
다음 예제를 보자.
import numpy as np
n_fft = 2048
ft = np.abs(librosa.stft(y[:n_fft], hop_length = n_fft+1))
plt.plot(ft)
plt.title('Spectrum')
plt.xlabel('Frequency Bin')
plt.ylabel('Amplitude')
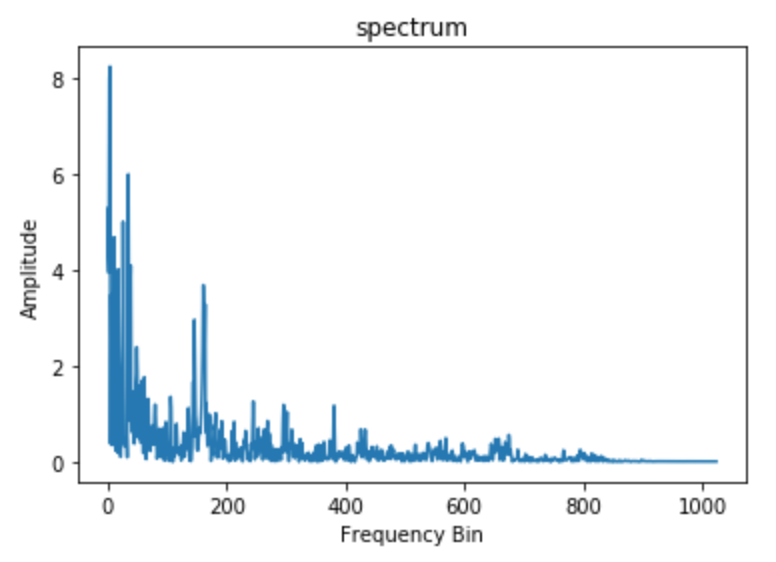
자, 그런데 뭔가 좀 이상하다.
FFT를 통해 얻은 spectrum에는 시간 정보가 없다!
음악이나 speech같은 non periodic한 audio signal은 주파수 정보가 시간마다 달라지기 때문에 FFT만 가지고는 사용할 수는 없다.
따라서, ‘음성 데이터를 시간 단위로 짧게 쪼개서 FFT를 해주자!’라는 해결책이 나왔고,
이것이 Short Time Fourier Transform이다.
- Short Time Fourier Transform(STFT) & Spectrogram
STFT를 통해 나오는 spectrogram은 서로의 위에 쌓인 FFT들의 묶음으로 생각할 수 있다.
각각 다른 주파수에 대해 시간이 지남에 따라 달라지기 때문에, spectrogram은 신호의 크기 또는 진폭을 시각적으로 보여줄 수 있다.
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max)
librosa.display.specshow(spec, sr=sr, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Spectrogram')
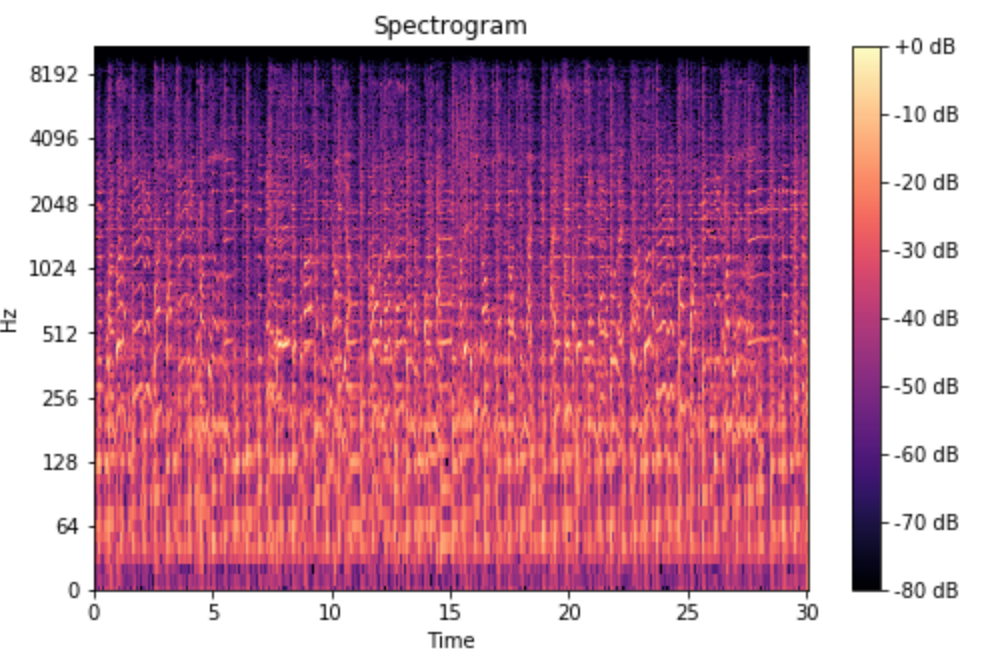
자, 먼 길 왔는데, 그래서 Mel-Spectrogram은 뭐냐..?
- Mel-Spectrogram
사람들은 음성 신호를 인식할 때 주파수를 linear scale로 인식하는게 아니라고 한다.
또, 낮은 주파수를 높은 주파수보다 더 예민하게 받아들이는데, 예를 들어 500 ~ 1000 Hz 가 바뀌는건 예민하게 인식하는데 10000Hz ~ 20000 Hz가 바뀌는 것은 잘 인식 못한다는 것이다.
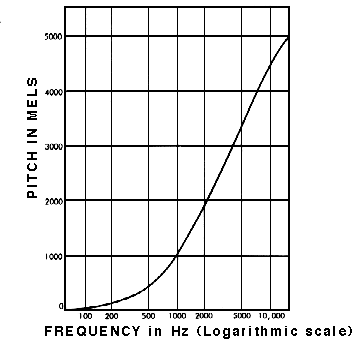
동일한 pitch distance면 듣는 사람으로 하여금 동일한 정도로 멀리 들리도록하는 pitch 단위를 제안했는데, 이를 mel scale이라고 하고, 이 주파수를 mel scale로 볼 수 있게 한 것이다.
앞선 spectrogram에 mel scale을 적용하면 Mel-Spectrogram을 만들 수 있다.
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time')
plt.title('Mel Spectrogram')
plt.colorbar(format='%+2.0f dB')
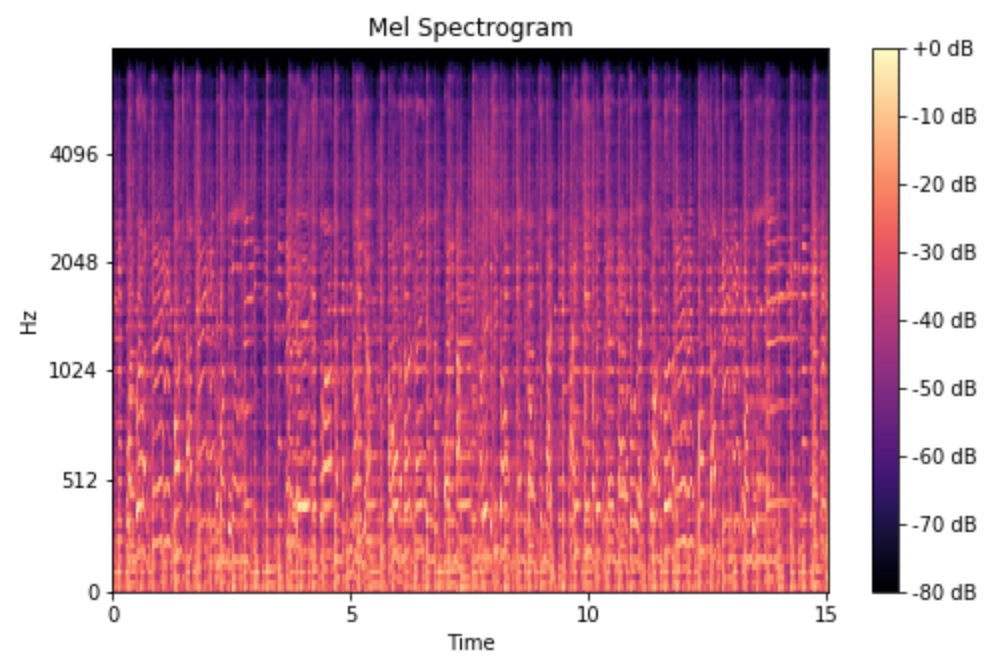
wave form의 생성
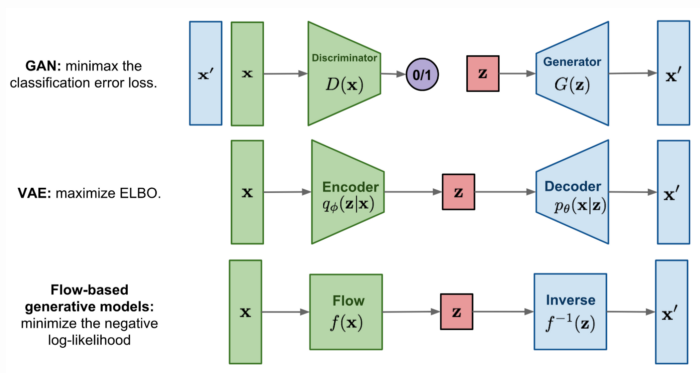
Glow-TTS와 Hifi-Gan에 대해서 이해하기 위해서는 먼저 Gan 모델에 대한 전반적인 이해가 필요하다.
- Gan Model
GAN은 생성자와 구분자로 구성되어있다. 구분자는 가짜 데이터가 포함된 전체데이터에서 실제 데이터를 구분해내는 학습을, 생성자는 실제와 비슷한 데이터를 생성해서 서로간 상호학습을 하는 방식이다.
- Flow-based generative models
연속적인 역변환을 통해서 생성하는 방식으로, 데이터의 분포에서 학습하는 방식이다.
그림을 보면 GAN과 VAE는 각각 구분자와 인코더 부분이 사다리꼴 모양인데, 이는 원본 데이터를 압축하는 것을 의미하고, 압축 및 확장하는 과정에서 데이터의 손실이 발생할 수 있다.
하지만 Flow-based 생성모델은 그림에서도 볼 수 있듯이 역함수 변환을 통해 데이터의 손실을 줄일 수 있다.
Glow-TTS & Hifi-Gan
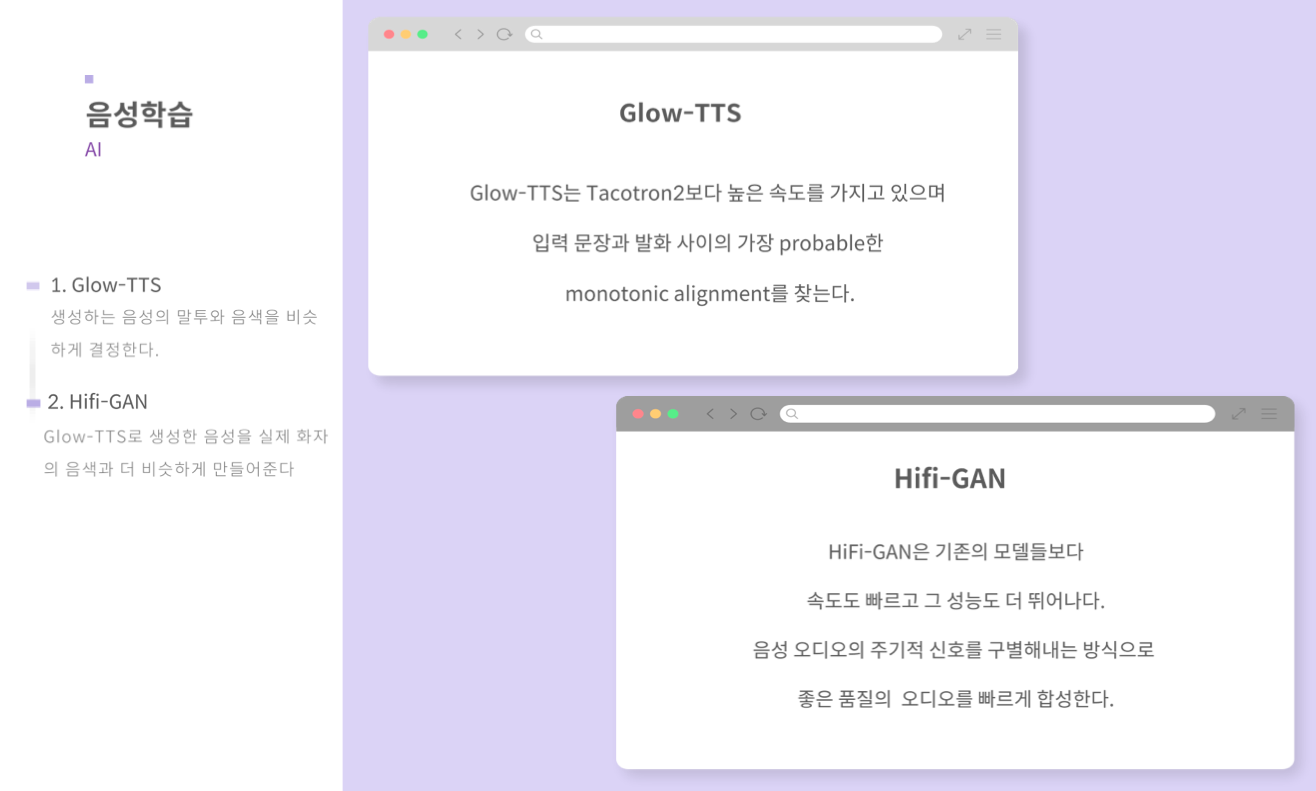
Glow-TTS 모델은 ‘Flow-based generative model’ for parallel TTS를 제안한다.
Hifi-Gan 모델은 ‘Gan Model’에서 discriminator를 sub-discriminators로 만들어 기존의 것보다 성능을 높인 것이 특징이다.
각각의 모델을 처음 제안한 ‘카카오엔터프라이즈의 기술블로그’에 자세히 설명되어있으니 그 내용을 인용하겠다.
- Glow-TTS
FastSpeech와 ParaNet 같은 최신 음성합성(TTS) 모델은 발화를 병렬적으로 합성(non-Autoregressive)해 그 속도를 높인 새로운 보코더(vocoder)를 제안했습니다. 하지만 이런 병렬 모델이 텍스트를 구성하는 음소 순서대로 오디오를 정렬하기 위해서는 따로 훈련된 Autoregressive 모델의 지원이 반드시 필요합니다.
이에 AI Lab은 정렬 모델을 따로 구축하지 않고도 이를 보다 정확하게 추정하는 새로운 TTS 모델인 Glow-TTS를 제안했습니다. Glow-TTS는 플로우 기반 생성 모델(flow-based generative models)과 동적 프로그래밍(dynamic programming)의 속성을 활용해 입력된 텍스트 순서에 따라 발화를 차례대로 정렬합니다(monotonic alignment).
그 결과, 매우 긴 텍스트로 빠르게 합성함은 물론, 서로 다른 강세와 억양을 갖춘 발화를 생성할 수 있습니다. 자체 실험에서 Glow-TTS는 autoregressive 모델인 Tacotron 2과 비교해 비슷한 품질의 음성을 약 15배 더 빠르게 생성했습니다. 또한 Glow-TTS가 다화자 음성합성 태스크에도 쉽게 적용될 수 있음을 확인했습니다.
- Hifi-Gan
최근 음성합성 연구에서는 GAN(generative adversarial networks) 구조를 활용해 보코더(vocoder)의 음성 합성 속도와 메모리 효율을 높이는 시도가 있었습니다. 하지만 이런 방식의 보코더가 합성한 음성의 품질은 Autoregressive 모델이나 플로우 기반의 생성 모델(flow-based generative model)에 미치지 못했습니다. 이에 AI Lab은 음성 오디오의 주기적 신호를 구별해내는 방식으로 기존 제안된 모델보다 월등히 좋은 품질의 오디오를 빠르게 합성하는 HiFi-GAN을 제안했습니다.
AI Lab은 메모리 효율성 및 속도와 관련된 초매개변수(hyperparameter)를 조정하고, 이 값을 조합한 3가지 버전의 세부 모델로 실험을 진행했습니다. 첫 번째 버전은 인간과 비슷한 수준의 고품질 오디오를 실시간의 167.9배 속도로 합성합니다. 두번째 버전은 비교 모델 중 가장 적은 매개변수를 사용하면서도 가장 좋은 음질을 생성합니다. 세 번째 버전은 GPU에서 실시간의 1,186.8배, CPU에서 13.4배 더 빠르게 기존 모델과 비슷한 품질의 오디오를 합성합니다.
다음 글 소개
사실 사용된 AI 기술에 대해서 깊게 들어가면 논문도 살펴봐야되고 끝없이 들어가야하지만, 이 프로젝트는 AI 기술 자체에 초점을 맞춘 것은 아니라서 간단하게만 다뤄보았다.
새삼 다시 느낀거지만 AI는 컴퓨터랑 관련이 있다기보단 그 자체로 다른 하나의 학문이라는 생각이 든다..
다음 글에서는 이 프로젝트를 배포하고 난 뒤, 쌓이게 되는 사용자들의 데이터를 어떻게 활용할 수 있는지를 살펴보자!
Reference
1) https://sce-tts.github.io/#/v2/train [TTS 모델학습]
2) https://medium.com/analytics-vidhya/understanding-the-mel-spectrogram-fca2afa2ce53
[Understanding the Mel Spectrogram]
3) https://sofar-sogood.tistory.com/entry/Glow-TTS-Glow-TTS-A-Generative-Flow-for-Text-to-Speech-via-Monotonic-Alignment-Search-NIPS-20
[Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search (NIPS 20)]
4) https://sofar-sogood.tistory.com/entry/Hifi-GAN-HiFi-GAN-Generative-Adversarial-Networks-for-Efficient-and-High-Fidelity-Speech-Synthesis-NIPS-20
[HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis (NIPS 20)]
5) https://tech.kakaoenterprise.com/94 [카카오엔터프라이즈 기술블로그 Tech&(테크앤):티스토리]
6) https://tech.kakaoenterprise.com/96 [카카오엔터프라이즈 기술블로그 Tech&(테크앤):티스토리]
7) https://medium.com/@sunwoopark/slow-paper-glow-generative-flow-with-invertible-1x1-convolutions-837710116939
[Glow: Generative Flow with Invertible 1x1 Convolutions]
댓글 남기기