
[Team_ForV] Flask Model Server
카테고리: Team_ForV
Flask Model Server의 역할
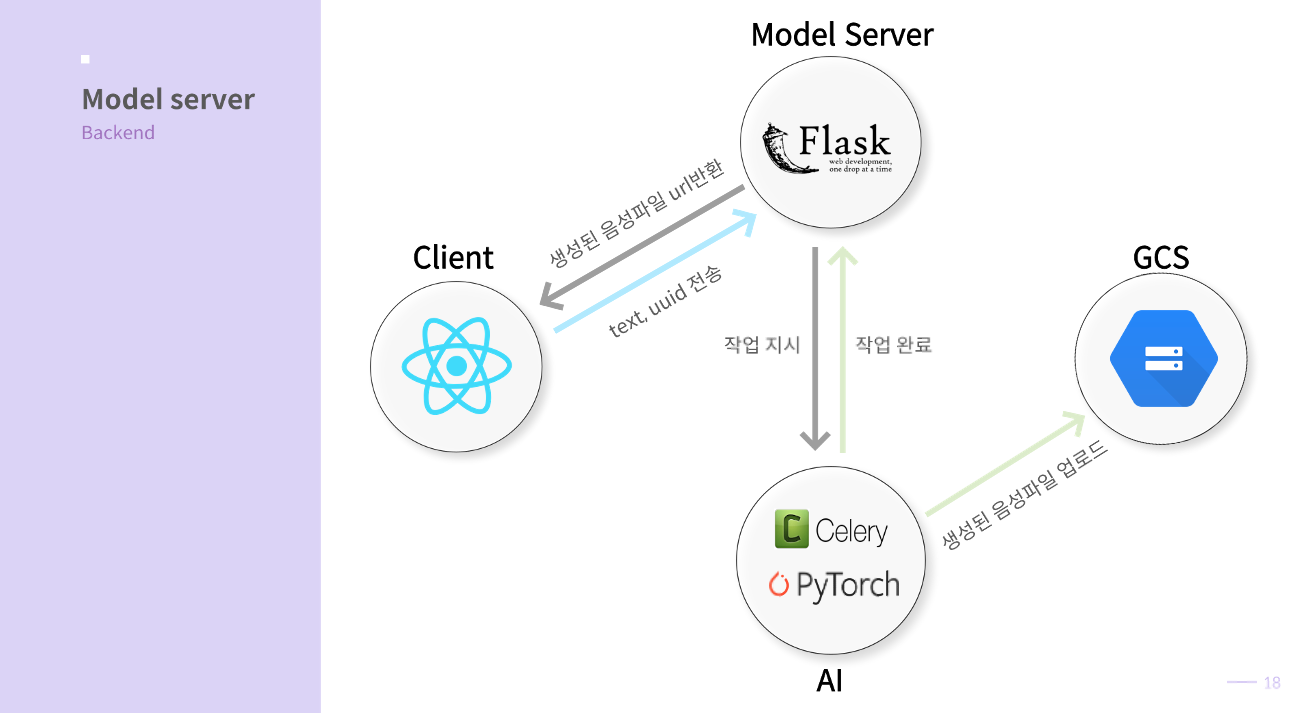
Flask Model Server는 단 한 가지 역할만 수행한다.
클라이언트로부터 음성 합성 요청을 받으면
-> flask 서버가 celery에게 task를 할당하고
-> celery worker가 task를 수행한다.
-> 여기서 task는 ‘입력받은 text를 지정된 멤버의 음성으로 wav 파일을 만들어 gcs에 업로드하는 것’이다.
-> task를 끝내면 celery worker가 flask에게 작업이 완료됨을 알려주고, flask는 클라이언트에게 알려준다.
-> 클라이언트는 google cloud storage에 업로드된 wav파일의 url을 통해서 생성된 음성파일을 재생한다.
이처럼, flask 서버는 ‘TTS 음성 합성과 연관된 작업’만을 수행하도록 구성하였는데,
flask 프레임워크의 특징을 보면서 model server로 flask를 선택한 이유를 살펴보자!
Flask에 대하여..

flask는 마이크로 웹 프레임워크다.
즉 간결하게 유지하고 확장할 수 있음을 의미한다.
간결하다는 것은? -> 짧은 코드만으로도 완벽히 동작하는 웹 프로그램을 만들 수 있다.
확장성 있는 설계? -> 플라스크에는 다양한 확장 모듈을 통해 입맛대로 만들 수 있다.
서버를 분리한 이유가 음성합성만을 하는 서버가 필요했기 때문이고, 이를 위해선
간단한 코드 구성만으로도 빠르게 뜨는 웹 프로그램이 필요했다. 따라서 model 서버로는 flask가 적절하겠다고 판단했다.
rabbitMQ & celery를 사용한 비동기처리
python 서버는 사용자의 요청이 수행되는 동안 또다른 요청이 들어올 시에 앞선 요청이 수행될 때까지 대기하고 있게 된다. 이는 다중 사용자가 서비스를 이용하기에 매우 안 좋은 환경이다.
따라서, rabbitMQ와 celery를 이용하여 비동기처리를 하도록 만들었다.
파일들을 하나씩 뜯어보며 살펴보자.
- celery app
celery app을 생성하고 세부 항목들을 설정한다.
- Celery App의 이름.
- broker: 처리할 Task를 보관하는 Broker(중계자)
- backend: 처리된 결과를 보관하는 Broker를 설정, 이를 생략하면 Task의 실행 결과를 받을 수 없음.
- include: Worker가 처리할 Task를 지정.
# celery_app.py: Celery App을 생성하는 파일
from celery import Celery
app = Celery('celery',
broker='amqp://tts:tts123@rabbit/tts_host',
backend='rpc://',
include=['voice'],
)
- task
총 세 부분으로 구성되어있다.
- 음성 합성을 위해 각 멤버들에 대한 변수들을 설정하여 models 리스트에 저장해둔다.
- celery app에 등록되어있는 task가 호출되면 전달된 인자들을 기반으로 wav 파일을 만들고,
- 서버에 저장하는 것이 아닌 google-cloude-storage에 저장한 후 True를 반환한다.
# voice.py: Worker의 Task가 담겨있는 파일
from celery_app import app
import os
from google.cloud import storage
from tts_modules import normalize_text
from TTS.TTS.utils.synthesizer import Synthesizer
############################################################################################################
models = [] # models => [[id1_syn, id1_symbol], [id2_syn, id2_symbol], [id3_syn, id3_symbol], ...]
for i in range(1,6):
member = []
print(f'member {i} synthesizer start!!')
# set synthesizer
synthesizer = Synthesizer(
f"./voice_model/glow-tts/{i}/{i}g_checkpoint_30000.pth.tar",
f"./voice_model/glow-tts/{i}/{i}g_config.json",
None,
f"./voice_model/hifigan-v2/{i}/{i}h_checkpoint_305000.pth.tar",
f"./voice_model/hifigan-v2/{i}/{i}h_config.json",
None,
None,
False,)
symbol = synthesizer.tts_config.characters.characters # normalize_text가 호출될 때 필요한 변수
member.append(synthesizer)
member.append(symbol)
models.append(member)
print(f'member {i} synthesizer end!!')
############################################################################################################
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]="./micro-handler.json" # wav gcp bucket 업로드를 위한 key path
bucket_name = 'forv_bucket' # 서비스 계정 생성한 bucket 이름 입력
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
# source_file_name = '' # GCP에 업로드할 파일 절대경로
# destination_blob_name = '' # 업로드할 파일을 GCP에 저장할 때의 이름
# blob = bucket.blob(destination_blob_name)
# blob.upload_from_filename(source_file_name)
############################################################################################################
@app.task(name="gan_wav")
def gan_wav(uuid, member_id, text, created_at):
wav_file = f'wav_files/{member_id}/{uuid}_{created_at}_voice.wav'
wav_path = f'./temp/{member_id}_{uuid}_{created_at}_voice.wav'
# 미리 만들어둔 객체를 참조
synth = models[int(member_id) -1][0]
sym = models[int(member_id) -1][1]
# g2pk 라이브러리를 이용한 입력된 텍스트 변환
n_text = normalize_text(text, sym)
wav = synth.tts(n_text, None, None)
synth.save_wav(wav, wav_path) # change wav to .wav file
blob = bucket.blob(wav_file)
blob.upload_from_filename(wav_path) # upload wav file to gcp bucket
if os.path.isfile(wav_path):
os.remove(wav_path)
return True
- flask app
특정 http 요청이 들어왔을 때 celery worker에게 작업을 수행하도록 만든다.
# app.py: Task를 실행시킬 파일
import time
from flask import Flask, request
from flask_cors import CORS
from voice import gan_wav # import celery task
app = Flask(__name__)
cors = CORS(app, resources={r"/*": {"origins": "*"}}) # react와 연결을 위한 cors 설정
@app.route('/')
def hello_world():
return {'result': 'hello world!'}
@app.route('/api/texts', methods = ['POST'])
def get_text():
'''
{
"uuid": "022db29c-d0e2-11e5-bb4c-60f81dca7676",
"member_id": 1,
"text": "안녕하세요!",
"created_at": "2022-08-22"
}
'''
if request.method == 'POST':
params = request.get_json()
uuid = params['uuid']
member_id = params['member_id']
text = params['text']
created_at = params['created_at']
gan_wav = gan_wav.delay(uuid, member_id, text, created_at) # celery task에 인자 전달
while True: # celery worker가 task를 완료하기를 기다림
if gan_wav.ready() == False:
time.sleep(5)
continue
else:
return {'uuid': uuid, 'member_id': member_id, 'created_at': created_at}
다음 글 소개
음성 합성에 필요한 핵심적인 부분은 tts와 g2pk라는 라이브러리이다.
이 라이브러리를 사용할 때 가장 곤란했던 점이 ‘라이브러리들끼리의 의존성’ 문제였다.
ai 관련 라이브러리들을 서로 의존성이 강하기 때문에 버전이 하나만 틀어져도 실행이 안 되는 경우가 많았고,
이로 인해 django서버와 flask서버의 python 버전을 다르게 구성을 해야했다.
결론부터 말하자면 이 문제를 해결하기위해 Docker를 도입했다.
다음 게시글에서는 이 프로젝트에 쓰인 ai 관련 라이브러리들과 Docker 세팅에 대해 알아보자.
Reference
1) https://leffept.tistory.com/202 [Flask 란?]
2) https://heodolf.tistory.com/63 [Celery 무작정 시작하기 (2) - Task]
3) https://buildabetterworld.tistory.com/144?category=874656
[Celery Side-Project(Ant Platform) - 3. Flask에서 Celery로 비동기작업 수행하기(프로젝트 구조+Celery동작)]
댓글 남기기