
[윤성우의 열혈 Java 프로그래밍] Chapter 34 - 쓰레드 그리고 동기화
카테고리: Java lang
태그: java
34-1. 쓰레드의 이해와 쓰레드의 생성
- 쓰레드의 이해와 쓰레드의 생성 방법
실행중인 프로그램(프로세스) 내에서 ‘또 다른 실행의 흐름을 형성하는 주체’를 의미한다.

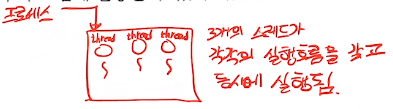
- 쓰레드를 생성하는 방법
코드 레벨에서 쓰레드는 생성하는 과정은 다음과 같다.
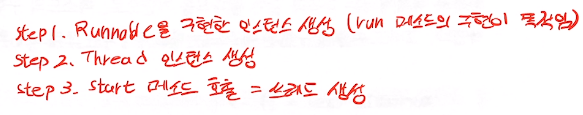
코드를 보면서 좀 더 알아보자.
public class MakeThreadDemo {
public static void main(String[] args) {
// Runnable을 구현한 인스턴스 생성
Runnable task = () -> {
int n1 = 10;
int n2 = 20;
String name = Thread.currentThread().getName();
System.out.println(name + ": " + (n1 + n2));
};
// Thread 인스턴스 생성
Thread t = new Thread(task);
// start 메소드 호출 == Thread 생성 및 실행
t.start();
System.out.println("End " + Thread.currentThread().getName());
}
}
# 실행 결과
End main
Thread-0: 30
main 쓰레드가 먼저 종료된 것을 볼 수 있다. 쓰레드의 생성에는 시간이 걸리므로 충분히 가능한 상황이다.
모든 쓰레드가 일을 마치고 소멸되어야 프로그램이 종료된다.
또, 위와 같이 생성된 쓰레드는 자신의 일을 마치면 자동으로 소멸(쓰레드의 생성을 위해 할당했던 모든 자원의 해제)된다.
쓰레드는 자신의 일을 마치면(run 메소드의 실행을 완료하면) 자동으로 소멸된다.
보통은 쓰레드 하나에 CUP의 코어 하나가 할당되어 동시에 실행이 이뤄진다.
여러 쓰레드가 실행되는 경우에는 이들은 코어를 나누어 차지하며 실행을 이어 나간다. 다만, 나누는 시간의 조각이 매우 작기 때문에 동시에 실행되는 효과를 충분히 누릴 수 있는 것이다.
또, 쓰레드가 처한 상황에 따라서, 또는 운영체제가 코어를 쓰레드에 할당하는 방식에 다라서 두 쓰레드의 실행 속도에는 차이가 있을 수 있기 때문에, 여러 쓰레드가 동작할 경우, 그 결과를 쉽게 예상하기란 어렵다.
다음 코드를 보면 알 수 있다.
public class ThreeMultiNoSleepDemo {
public static void main(String[] args) {
Runnable task1 = () -> {
for (int i = 0; i < 20; i++) {
if (i % 2 == 0) { // 짝수 출력
System.out.print(i + " ");
}
}
};
Runnable task2 = () -> {
for (int i = 0; i < 20; i++) {
if (i % 2 != 0) { // 홀수 출력
System.out.print(i + " ");
}
}
};
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.start();
t2.start();
}
}
# 첫 번째 실행
1 0 3 2 5 7 4 6 9 8 11 10 13 12 15 14 17 16 19 18
# 두 번재 실행
0 2 4 6 8 1 3 5 10 12 14 7 9 11 16 18 13 15 17 19
# 세 번째 실행
1 3 5 7 9 11 13 15 17 19 0 2 4 6 8 10 12 14 16 18
여기서 보이듯이 각각의 쓰레드는 이렇게 독립적으로 자신의 일을 실행해 나간다.
- 쓰레드를 생성하는 두 번째 방법
다음과 같이 Thread 클래스를 상속하여 task를 구성할 수도 있다.
class Task extends Thread {
@Override
public void run() {
int n1 = 10;
int n2 = 20;
String name = Thread.currentThread().getName();
System.out.println(name + ": " + (n1 + n2));
}
}
class Main {
public static void main(String[] args) {
Task t1 = new Task();
Task t2 = new Task();
t1.start();
t2.start();
System.out.println("End " + Thread.currentThread().getName());
}
}
34-2. 쓰레드의 동기화
- 쓰레드의 메모리 접근 방식과 그에 따른 문제점
쓰레드를 설명할 때 사용하는 단골 예시를 들어보자.
class Counter {
int count = 0;
synchronized public void increment() {
count++;
}
synchronized public void decrement() {
count--;
}
public int getCount() {
return count;
}
}
public class MutualAccess {
public static Counter cnt = new Counter();
public static void main(String[] args) throws InterruptedException {
Runnable task1 = () -> {
for (int i = 0; i < 1000; i++) {
cnt.increment();
}
};
Runnable task2 = () -> {
for (int i = 0; i < 1000; i++) {
cnt.decrement();
}
};
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.start();
t2.start();
// main 쓰레드가 다른 두 쓰레드의 실행이 완료되기를 기다리기 위해 추가
t1.join();
t2.join();
System.out.println(cnt.getCount());
}
}
# 실행결과 1
2
# 실행결과 2
0
# 실행결과 3
4
결과를 보면 당연히 결과가 0이 될 것이라는 예상과는 다르게 실행할 때마다 다른 결과가 나오는 것을 볼 수 있다.
따라서 자연스럽게 다음을 유추해 볼 수 있다.
둘 이상의 쓰레드가 동일한 변수에 접근하는 것은 문제를 일으킬 수 있다.
그리고 이럴 때 필요한 개념이 바로 동기화(synchronization)이다.
- 동일한 메모리 공간에 접근하는 것이 왜 문제가 되는가?
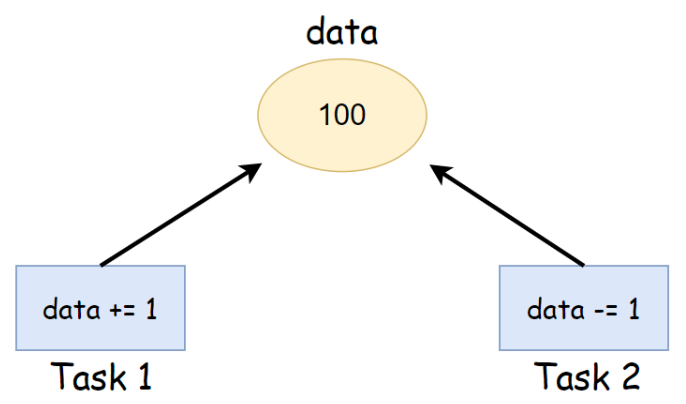
다음과 같이 서로 다른 쓰레드가 같은 자원에 동시에 접근한다고 가정하자.
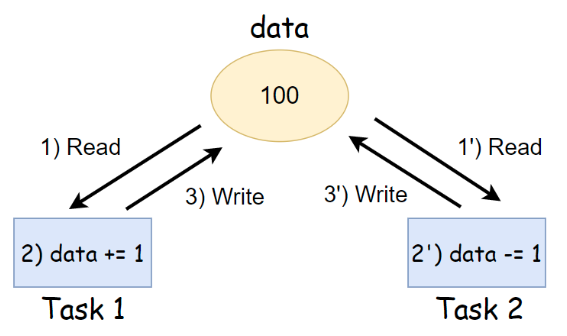
값을 바꾸려면
- data에서 값을 가져오고
- 가져온 값을 증가 시키고
- 증가시킨 값을 다시 data에 할당하기
위 세 가지 동작 과정을 거쳐야 한다.
하지만, 코어가 여러 개일 때나 코어가 단일 코어더라도 쓰레드가 코어를 나누어 차지하는 시간 조각이 굉장이 작기 때문에 여러 쓰레드가 거의 동시에 값을 가져가는 상황이 생길 수 있다.
이럴 경우에는 위의 그림과 같이 task1이 완전히 끝나기 전에 task 2에서 결과를 가져갈 수도 있는 것이다.
따라서, 둘 이상의 쓰레드가 동일한 변수에 동시에 접근하는 상황에서는 한 순간에 한 쓰레드만 변수에 접근하도록 제한할 필요가 있다.
- 동기화(Synchronization) 메소드
다음과 같이 synchronized 키워드를 통해 메소드 단위로 동기화를 걸 수 있다.
class Counter {
int count = 0;
synchronized public void increment() {
count++;
}
synchronized public void decrement() {
count--;
}
public int getCount() {
return count;
}
}
위와 같이 ‘한 클래스의 두 메소드’에 synchronized 선언이 되면, 두 메소드는 둘 이상의 쓰레드에 의해 동시에 실행될 수 없도록 동기화된다.
- 동기화(Synchronization) 블록
메소드 전체로 묶을 필요가 없을 때는 다음과 같이 동기화 블록을 사용하는 방법도 있다.
class Counter {
int count = 0;
public void increment() {
synchronized (this) {
count++;
}
}
public void decrement() {
synchronized (this) {
count--;
}
}
public int getCount() {
return count;
}
}
여기서 this는 Counter 클래스의 인스턴스를 말한다.
즉, Counter 클래스의 인스턴스 내에 위치한 두 동기화 블록은 둘 이상의 쓰레드의 의해 동시에 실행될 수 없도록 함께 동기화된다.
34-3. 쓰레드를 생성하는 더 좋은 방법
- 지금 소개하는 이 방법으로 쓰레드를 생성하고 활용하자.
쓰레드의 생성과 소멸은 그 자체로 시스템에 부담을 준다.
따라서, 쓰레드 풀(Thread Pool)을 만들고 그 안에서 미리 제한된 수의 쓰레드를 생성해 두고 이를 재활용하는 기술을 사용한다.
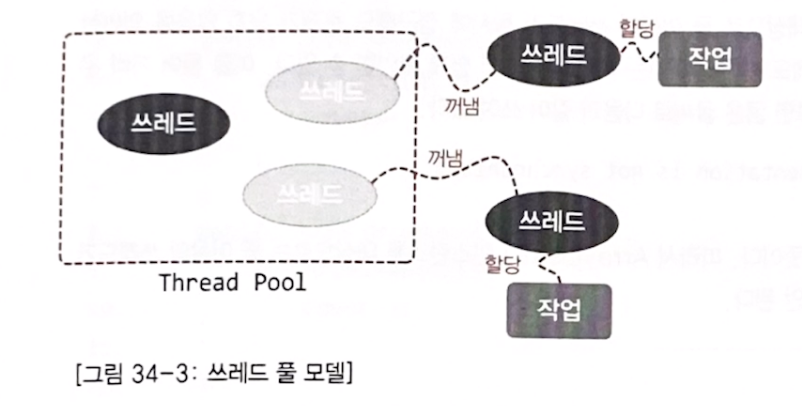
다만, 직접 구현할 필요는 없고, 자바에서 제공하는 concurrent 패키지를 활용하면 된다.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ExecutorsDemo {
public static void main(String[] args) {
Runnable task = () -> {
int n1 = 10;
int n2 = 20;
String name = Thread.currentThread().getName();
System.out.println(name + ": " + (n1 + n2));
};
ExecutorService exr = Executors.newSingleThreadExecutor();
exr.submit(task); // Thread Pool에 작업을 전달
System.out.println();
exr.shutdown(); // Thread Pool과 그 안에 있는 Thread의 소멸
}
}
# 실행 결과
pool-1-thread-1: 30
위의 코드는 싱글쓰레드풀을 생성했지만 Executors 클래스의 여러 메소드들을 통해 다양한 유형의 쓰레드 풀을 생성할 수 있다.
// 1. 풀 안에 하나의 쓰레드만 생성하고 유지한다.
ExecutorService exr1 = Executors.newSingleThreadExecutor();
// 2. 풀 안에 인자로 전달된 수의 쓰레드를 생성하고 유지한다.
ExecutorService exr2 = Executors.newFixedThreadPool(3);
// 3. 풀 안의 쓰레드의 수를 작업의 수에 맞게 유동적으로 관리한다.
ExecutorService exr3 = Executors.newCachedThreadPool();
다른 쓰레드 풀을 사용하여 여러 task를 전달해보자.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ExecutorDemo2 {
public static void main(String[] args) {
Runnable task1 = () -> {
String name = Thread.currentThread().getName();
System.out.println(name + ": " + (5 + 7));
};
Runnable task2 = () -> {
String name = Thread.currentThread().getName();
System.out.println(name + ": " + (5 - 7));
};
ExecutorService exr = Executors.newFixedThreadPool(2);
exr.submit(task1);
exr.submit(task2);
exr.submit(() -> {
String name = Thread.currentThread().getName();
System.out.println(name + ": " + (5 * 7));
});
exr.shutdown();
}
}
- Callable & Future
Runnable에 위치한 추상 메소드 run의 반환형은 void이기 때문에 작업의 결과를 받을 수 없다.
이럴 경우, 다음 인터페이스를 기반으로 작업을 구성하면 작업의 끝에서 값을 반환하는 것이 가능하다.
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
Callable 인터페이스와 Future 인터페이스를 통해 쓰레드가 처리한 작업에 대한 결과를 얻을 수 있다.
import java.util.concurrent.*;
public class CallableDemo {
public static void main(String[] args) throws Exception {
Callable<Integer> task = () -> {
int n = 0;
for (int i = 0; i < 10; i++) {
n += i;
}
return n;
};
ExecutorService exr = Executors.newSingleThreadExecutor();
Future<Integer> fur = exr.submit(task);
int result = fur.get();
System.out.println(result);
exr.shutdown();
}
}
- synchronized를 대신하는 ReentrantLock
동기화 블록 대신 ReentrantLock 인스턴스를 이용하는 방법도 있다.
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.locks.ReentrantLock;
class CounterC {
int count = 0;
ReentrantLock criticObj = new ReentrantLock();
public void increment() {
criticObj.lock();
try {
count++;
} finally {
criticObj.unlock();
}
}
public void decrement() {
criticObj.lock();
try {
count--;
} finally {
criticObj.unlock();
}
}
public int getCount() {
return count;
}
}
public class MutualAccessReentrantLock {
public static CounterC cnt = new CounterC();
public static void main(String[] args) {
Runnable task1 = () -> {
for (int i = 0; i < 1000; i++) {
cnt.increment();
}
};
Runnable task2 = () -> {
for (int i = 0; i < 1000; i++) {
cnt.increment();
}
};
ExecutorService exr = Executors.newFixedThreadPool(2);
exr.submit(task1);
exr.submit(task2);
System.out.println(cnt.getCount());
exr.shutdown();
}
}
- 컬렉션 인스턴스 동기화
동기화는 그 특성상 어쩔 수 없이 성능의 저하를 수반한다.
이러한 이유로 컬렉션 프레임워크의 클래스 대부분도 동기화 처리가 되어 있지 않다.
따라서, 쓰레드의 동시 접근에 안전하지 않다. 대신 Collections의 다음 메소드들을 통해 동기화 방법을 제공하고 있다.
public static <T> Set<T> synchronizedSet(Set<T> s)
public static <T> List<T> synchronizedList(List<T> list)
public static <K, V> Map<K, V> synchronizedMap(Map<T> m)
public static <T> Collections<T> synchronizedCollection(Collection <T> e)
간단한 예시 코드를 보자.
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class SyncArrayList {
public static List<Integer> lst = Collections.synchronizedList(new ArrayList<>());
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 16; i++) {
lst.add(i);
}
Runnable task = () -> {
// 컬렉션 인스턴스 자체에 대한 동기화되었다고 해도 이를 기반으로 생성된 반복자까지 동기화가 이뤄지는 것은 아니기 때문
synchronized (lst) {
ListIterator<Integer> itr = lst.listIterator();
while (itr.hasNext()) {
itr.set(itr.next() + 1);
}
}
};
ExecutorService exr = Executors.newFixedThreadPool(3);
exr.submit(task);
exr.submit(task);
exr.submit(task);
exr.shutdown();
exr.awaitTermination(100, TimeUnit.SECONDS);
System.out.println(lst);
}
}
Reference
[운영체제] Concurrency(동시성)과 Parallelism(병렬성) 이해하기
댓글 남기기